Giới thiệu:
Chào mừng bạn đến với SMCC - Nền tảng Hồ dữ liệu được thiết kế để tăng cường sức mạnh cho cá nhân và doanh nghiệp bằng cách thu thập, lưu trữ và xử lý lượng dữ liệu lớn. Hướng dẫn này sẽ giúp bạn hiểu cơ bản về cách bắt đầu và tận dụng tối đa các tính năng mạnh mẽ của SMCC. Để tìm hiểu về triết lí xây dựng SMCC, xin mời bạn truy cập
Triết lí Chọn lọc Thông tin.
Bắt đầu:
Tạo tài khoản: Để tạo tài khoản, nhấp vào nút 'Đăng ký', cung cấp địa chỉ email hợp lệ, tạo mật khẩu và hoàn thành quy trình xác minh email.
Đăng nhập: Nhập email đã đăng ký và mật khẩu vào các trường tương ứng, sau đó nhấp 'Đăng nhập' để truy cập tài khoản SMCC của bạn.
Thanh toán: Bạn có thể dùng thử SMCC trong vòng 7 ngày với các tính năng giới hạn và các dữ liệu cũ. Để dùng SMCC đầy đủ, xin mời bạn
Tham khảo Bảng giá SMCC và chọn mua gói thuê bao phù hợp.
Cài đặt Data Picker: Truy cập
Trang Data Picker của SMCC, nhấp vào nút 'Bộ cài đặt Data Picker' và làm theo
hướng dẫn này để cài đặt Data Picker lên máy tính của bạn. Data Picker giúp bạn tùy ý thu nhận thông tin mạng xã hội để xử lí trên SMCC.
Tổng quan về giao diện:
Giao diện người dùng trực quan của SMCC bao gồm:
Dataverse Viewer: Đây là nơi tập trung các điểm dữ liệu nổi bật trong Hồ dữ liệu. Mỗi điểm dữ liệu dẫn tới một dataverse mới, chứa các bài viết nổi bật và thông tin thống kê. Các điểm dữ liệu được phân bố theo ngày lấy mẫu, có thể xem được từ 1/1/2016 trở lại đây.
Tạo Dataverse: Tại đây, bạn có thể khởi tạo các dạng Dataverse (các mô hình dữ liệu) mà mình muốn phân tích chi tiết. Các mô hình dữ liệu có thể được tạo ra từ các từ khóa, hoặc các uid, hoặc danh sách các uid trên mạng xã hội.
Danh sách Dataverse: Phần này chứa danh sách các Dataverse đã được khởi tạo. Mỗi Dataverse này chứa nhiều thông tin chi tiết được phân tích, thống kê tự động bởi hệ thống AI của SMCC.
Thu thập dữ liệu:
SMCC có nhiều cơ chế thu thập dữ liệu như sau:
Thu thập dữ liệu tự động: Hệ thống robot của SMCC có khả năng tự rà quét các nguồn dữ liệu công khai như các trang báo điện tử, blog, diễn đàn và cả một số kênh mạng xã hội nổi bật.
Thu thập dữ liệu chủ động: Phần mềm SMCC Data Picker được cài đặt trên máy người dùng (dưới dạng phần mở rộng của trình duyệt Chrome) cho phép bạn chủ động thu thập dữ liệu từ các kênh mạng xã hội mà mình quan tâm và có thể truy cập.
Thu thập dữ liệu cộng tác: Các dữ liệu công khai được toàn bộ người dùng SMCC thu thập qua Data Picker được chia sẻ tự động với nhau để phục vụ làm giàu các phép thống kê.
Xử lý dữ liệu:
Công nghệ AI của SMCC sẽ tự động phân loại và sắp xếp dữ liệu của bạn. Quá trình này thường gồm các bước:
Thu nhận dữ liệu mẫu: Dữ liệu được chuyển về từ các nguồn robot hoặc Data Picker và được đưa vào hệ thống chờ xử lí.
Phân tích ngôn ngữ: Các dữ liệu cần xử lí được đưa qua các bộ phân tích, xử lí ngôn ngữ tự nhiên và trở nên có cấu trúc hơn, sẵn sàng cho việc thống kê, tìm kiếm.
Chọn lọc thông tin: Người dùng định nghĩa ra các vấn đề, chủ đề, từ khóa cần theo dõi, phân tích, chọn lọc thông tin và tạo ra các Dataverse (mô hình dữ liệu) để tìm lọc thông tin quý.
Tạo thông tin chi tiết:
Sử dụng các công cụ phân tích chi tiết trong Dataverse để có được cái nhìn sâu sắc về dữ liệu của bạn:
Tổng quan Dataverse: Cung cấp các điểm dữ liệu chính yếu xuất hiện trong Dataverse của bạn trong thời gian gần đây
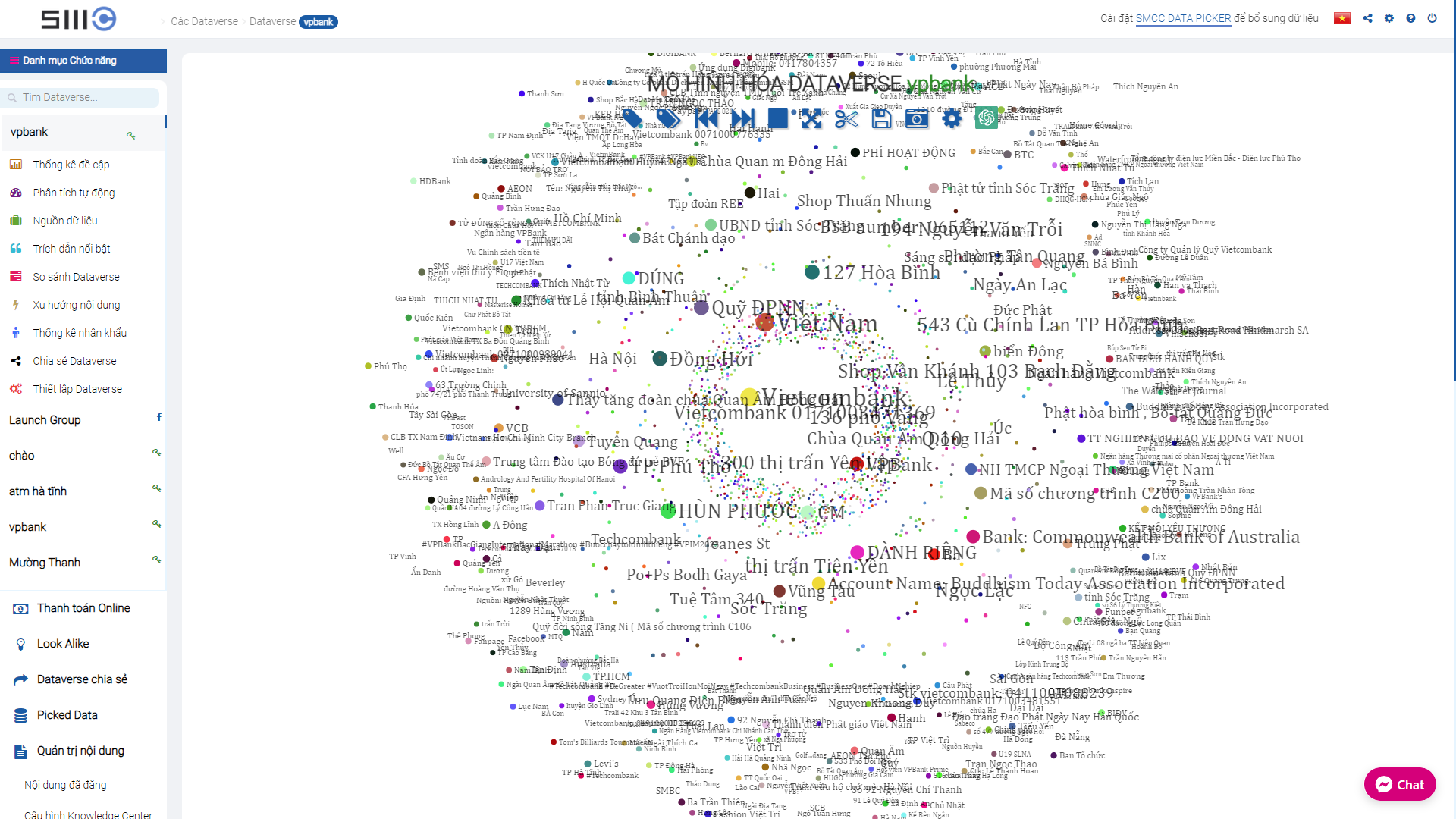
Thống kê đề cập: Biểu diễn phân bố dữ liệu theo thời đoạn thống kê và cùng các bộ lọc chuyên sâu giúp lọc dữ liệu theo nguồn tin và nhiều tiêu chí khác.
Phân tích tự động: Cung cấp nhiều insight được nội duy hoặc thống kê bởi AI, cho biết tình hình lan tỏa và tương tác của các thông tin trong Dataverse.
Trích dẫn nổi bật: Các trích dẫn nổi bật nhất xoay quanh các từ khóa tiêu điểm của Dataverse.
So sánh Dataverse: So sánh các chỉ số cơ bản của nhiều Dataverse với nhau.
Xu hướng nội dung: Phân tích xu hướng nội dung dựa trên các từ khóa nổi bật xuất hiện trong Dataverse.
Thống kê Nhân khẩu học: Thống kê thông tin nhân khẩu học của những nguồn đăng thông tin trong phạm vi của Dataverse. Các chỉ số nhân khẩu học của mỗi nguồn tin được dự báo bởi AI.
Bảo mật và quyền riêng tư:
SMCC ưu tiên hàng đầu cho bảo mật:
Phi định danh hóa: Tất cả dữ liệu trong SMCC được loại bỏ các định danh có thể gây nguy hại cho cá nhân như số điện thoại, email...
Trộn lẫn UID: Các UID xuất ra từ Dataverse trên SMCC được trộn lẫn để tránh xác định chính xác người dùng mạng xã hội trên số lượng lớn.
Khắc phục sự cố:
Phần khắc phục sự cố của chúng tôi cung cấp giải pháp cho các vấn đề thường gặp:
Tài nguyên trợ giúp thêm:
Có nhiều tài nguyên khác nhau có sẵn để hỗ trợ thêm như Kênh YouTube, Kênh Facebook của SMCC, xin mời bạn xem tại
Danh mục chức năng của SMCC
Xin lưu ý, đây chỉ là hướng dẫn bắt đầu nhanh - để hiểu chi tiết hơn về các tính năng của SMCC, vui lòng tham khảo hướng dẫn sử dụng chi tiết hoặc tài liệu chính thức khác.